Text can be used to improve semantic understanding of human poses:
Downward Dog Yoga pose (Wikipedia)

"The pose has the head down, ultimately touching the floor, with the weight of the body on the palms and the feet. The arms are stretched straight forward, shoulder width apart; the feet are a foot apart, the legs are straight, and the hips are raised as high as possible."
Gaining semantic understanding of human poses would open the door to a number of applications such as pose teaching, pseudo 3D annotation when deploying a MoCap system is complicated, digital pose generation, or search for complex poses in large-scale datasets.
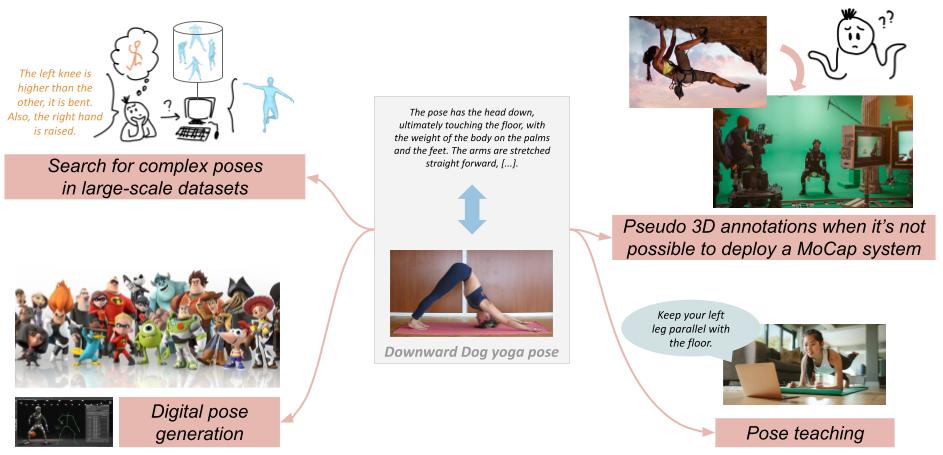
For this purpose, we introduce the PoseScript dataset, which pairs a few thousand 3D human poses from AMASS with rich human-annotated descriptions of the body parts and their spatial relationships.
To increase the size of this dataset to a scale compatible with typical data hungry learning algorithms, we propose an elaborate captioning process that generates automatic synthetic descriptions in natural language from given 3D keypoints.
We show applications of the PoseScript dataset to:
- retrieval of relevant poses from large-scale datasets, and
- synthetic pose generation,
both based on a textual pose description.

The PoseScript dataset is composed of:
- a set of 100k diverse 3D human poses extracted from AMASS
- ~6k human-written descriptions: these were collected on Amazon Mechanical Turk by showing 3 additional poses, similar to the one to be annotated, so to obtain detailed & discriminative captions.

- 3 synthetic descriptions, in Natural Language, for each pose: these were generated automatically by a randomized captioning process which takes 3D keypoints as input, and extracts low-level pose information – the posecodes – thanks to a set of simple but generic rules. The posecodes are then combined into higher level textual descriptions using syntactic rules. This makes it possible to increase the size of this dataset to a scale compatible with typical data hungry learning algorithms, at no cost. The captioning pipeline produces 60k descriptions in the time it takes to write 1!

Here is an example of both a human-written caption and a synthetic one, for a given 3D human pose:

The human-written captions tend to be more straightforward, and may bear cultural references, while the automatically generated captions are more detailed, eg. “the right knee is forming a L shape”.
The Text-to-Pose retrieval model
We design a text-to-pose retrieval model, trained with contrastive learning: the encodings of the pose and its corresponding PoseScript description are brought close together in a joint embedding space, while elements from different data pairs are pushed apart.
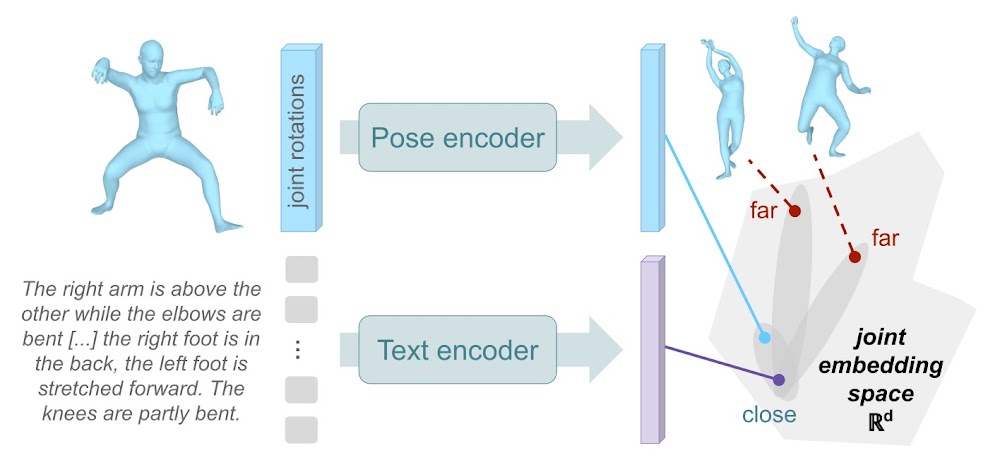
As a consequence, one can freely type a description text to query poses from a large database by looking at embedding similarity.
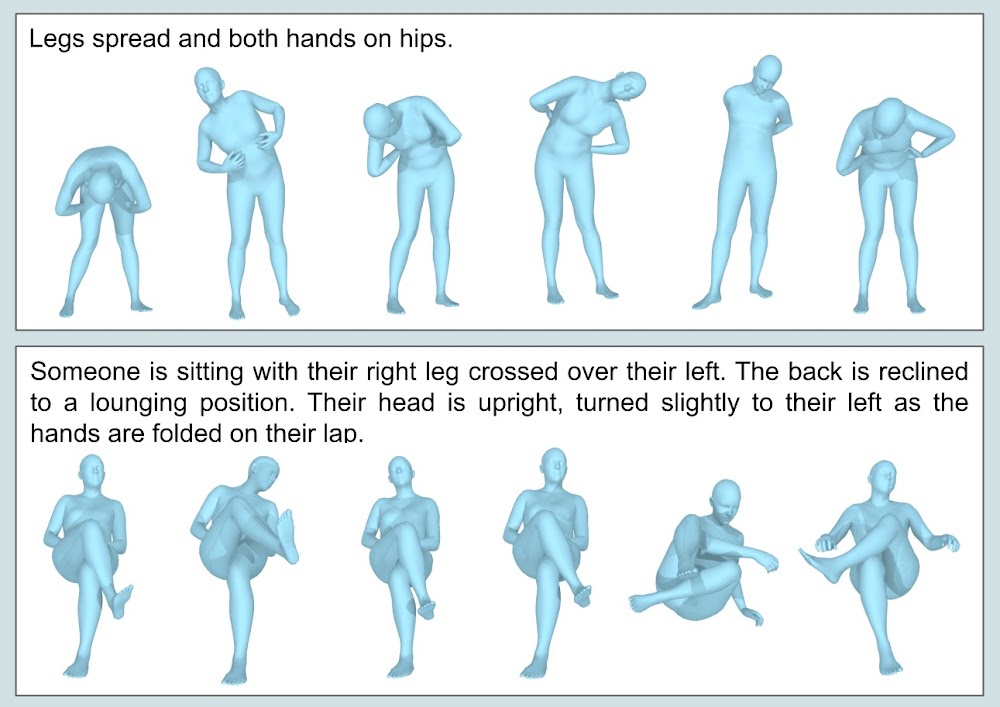
The more detailed the description, the more constrained the query, the less diverse the different retrieved poses.
It is also possible to retrieve images showing people in particular poses, provided that the images (here from MS-COCO) are associated with SMPL body fits (here EFT SMPL fits).

The text-conditioned pose generation model
Next, we design a text-conditioned pose generation model, such that, at test time, the text is encoded as a distribution, from which we sample a z that will then be decoded as a 3D body pose.
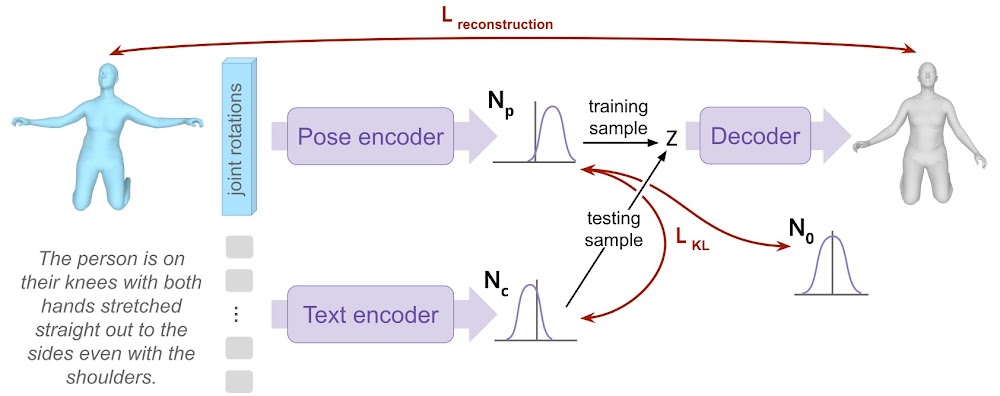
At train time, we also encode the initial pose, and sample from the corresponding distribution to decode it as a new pose, that will be compared to the initial pose, as in a regular variational auto-encoder. To make the model conditioned on text, we force the two distributions of pose and text to be aligned. We additionally regularize the pose distribution so to sample poses without conditioning on text.
See below some generation results:

This work is supported by the Spanish government with the project MoHuCo PID2020-120049RB-I00, and by NAVER LABS Europe under technology transfer contract 'Text4Pose'.
@inproceedings{delmas_posescript,
title={{PoseScript: Linking 3D Human Poses and Natural Language}},
author={{Delmas, Ginger and Weinzaepfel, Philippe and Lucas, Thomas and Moreno-Noguer, Francesc and
Rogez, Gr\'egory}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2024},
doi={10.1109/TPAMI.2024.3407570}
}