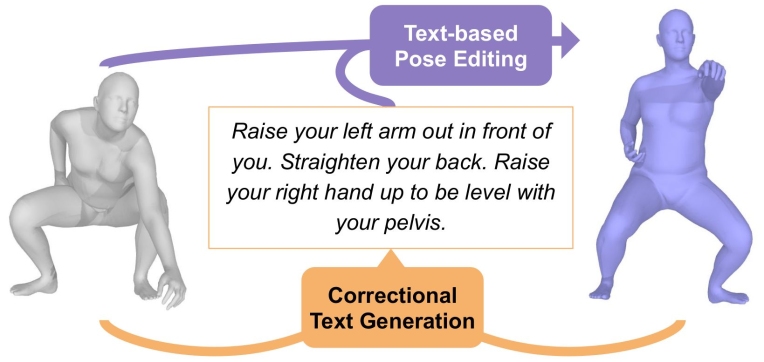
In this work we are interested in linking text to human pose through the following 3 elements:
a source pose, a target pose, and a text explaining how to correct the source pose to produce the target pose.
For this purpose we first introduce the PoseFix dataset, which contains thousands of such triplets.
Then we study two tasks, where the goal is to generate one element from the other two, specifically:
- Text-guided pose editing: generate the target pose from the source pose and the modifying text.
- Corrective text generation: generate the corrective instruction to obtain the target pose from the source pose.
Our work fits several applications. For instance,
correctional text generation could be used by a fitness application to help people correct their pose and avoid pain or injury.
Modifying texts could be used as auxiliary input to guide pose estimation from images in difficult cases; or
as instructions to modify a pose or a pose sequence in digital animation.
Although there is a number of related works, PoseFix is new in its kind:
it studies fine grained egocentric semantics instead of global semantics we find for motions (as in [HumanML3D: Guo et al., CVPR 2022]);
it does not focus on one pose (as in [PoseScript: Delmas et al., ECCV 2022]) but uses two, studying their relationship;
it uses text for control (instead, eg., of manual mouse dragging, [ProtoRes: Oreshkin et al., ICLR 2022]);
it generates feedback in natural language without resorting to predefined sentences (conversly to [AIFit: Fieraru et al., CVPR 2021]);
and it applies on 3D body poses, rather than 2D images (as in [FixMyPose: Kim et al., AAAI 2021]).

The PoseFix dataset is composed of pairs 3D human body poses extracted from AMASS [Mahmood et al., ICCV 2019].
The target poses were selected with a farther-point sampling algorithm, so as to form a diverse set of poses.
The source poses were selected based the target poses, following two criteria.
First, the source pose had to be similar enough to the target pose, so that writing about the target pose relatively to the source pose would not lead to a direct description of the target pose but to an actual modifying instruction.
Second, the source pose had to be different enough from the target pose, for the text annotation not to collapse to oversimple instructions.
The goal was to obtain rich modifying texts, to learn about fine-grained differences.
Then, we collected over 6 thousands human-written annotations on Amazon Mechanical Turk, and further adapted the automatic captioning pipeline from PoseScript to generate hundred of thousands automatic training annotations at no cost:
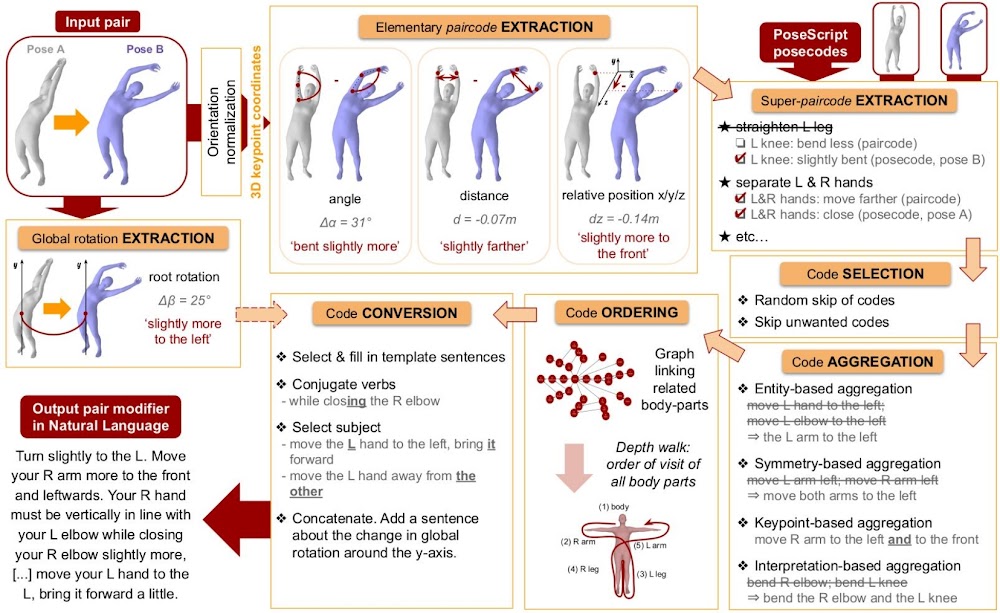
Below is an example of a human-written and an automatic annotation for a given pose pair:

The first task we consider is the text-guided pose editing task, where the goal is to modify the source pose based on the text indications.

We propose to tackle it with a conditional variational auto-encoder.
Both the source pose and the modifier text are encoded through modality-specific encoders, then fused thanks to a gating mechanism [TIRG: Vo et al., CVPR 2019], and encoded as a single "query" distribution. At test time, we sample a \(z\) from this distribution, that is decoded as a 3D body pose.
The pose encoder and the pose decoder are trained using the regular variational auto-encoder framework, thanks to a reconstruction loss that compares the encoded-decoded target pose to its original version. To make the model conditioned on the fusion of the source pose and the modifier text, we force the distribution of the pose and the distribution of the fused query to be aligned, thanks to the Kullback–Leibler divergence.

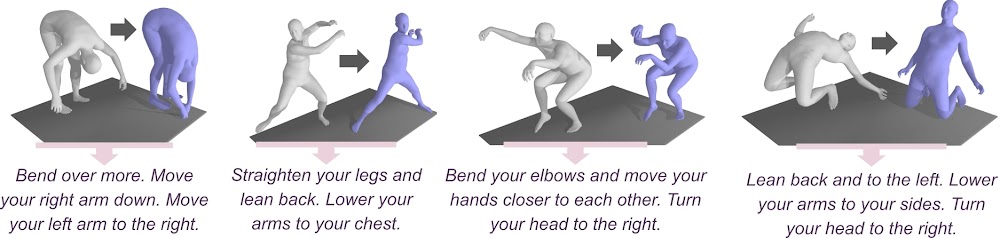
We show some results, where the generated pose both complies with the text instruction, and has some of its initial, un-mentioned characteristics preserved (eg. the leg opening):
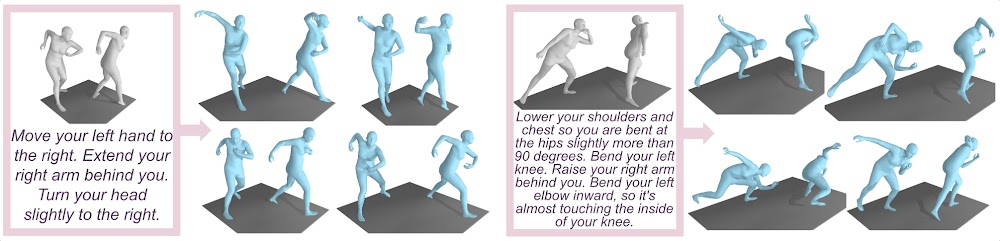
Corrective text generation
The PoseFix dataset also opens the door of the corrective text generation task, where the goal is to generate the instruction explaining how to go from the source pose to the target pose. This task finds application in sport coaching, to provide automatic feedback, based on the comparison of the user pose with the expected pose.

We build on top of a regular auto-regressive text generation model.
The poses are encoded using a shared encoder, their embedding are combined thanks to a fusing module, then they are injected by cross-attention in a transformer text decoder.
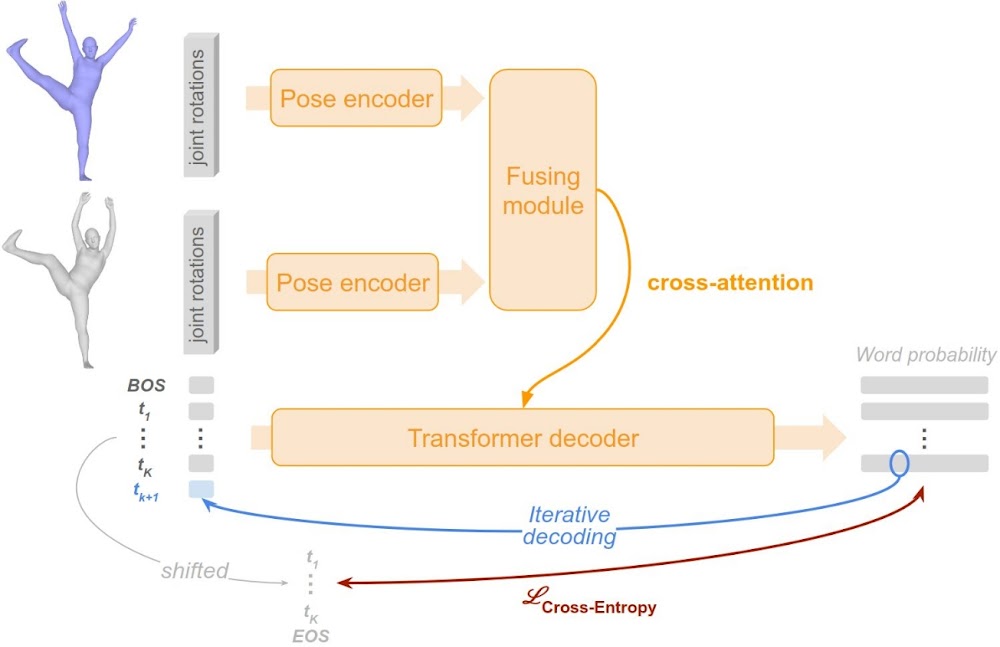
Transformer-based text generation basics: given the first \(K\) tokens, the decoder aims to predict token \(K+1\). The transformer takes token embeddings as input, and outputs a distribution of probability over the vocabulary, for each input token. The model is trained with a cross-entropy loss, such that the target of each token \(K\) is the token \(K+1\) (label shifting for parallel training). At test time, the generated text is obtained by greedy decoding: starting from the "Beginning Of Sequence" (BOS) token, we iteratively predict the next token as the word that maximizes the negative log likelihood (based on the word probability), and we proceed until we get the "End Of Sequence" (EOS) token.
The model generates textual instructions explaining how to modify the source pose to produce the target pose. It focuses on the main differences and is able to provide egocentric instructions (as "lower your arms to your chest").
A few words on the experiments
In a limited data context, experiments reveal the benefits of using data augmentation tricks such as mirroring (switching "left"/"right") and text paraphrases. It is also useful to consider added "degenerated data", such as single pose descriptions from PoseScript. However, what really improves performance is pretraining on the automatic PoseFix data, and more specifically, training on a large variety of poses. When pretraining, other studied data augmentation methods are much less impactful (if effective at all).
The results are promising, but there is still room for improvement.
For instance, the models struggle with rare poses and tend to ignore some differences or instructions. Sometimes, the text-guided pose editing model also fails to preserve some traits of the source pose; and the corrective text generation model mixes up the source and target poses.
This work is supported by the Spanish government with the project MoHuCo PID2020-120049RB-I00, and by
NAVER LABS Europe under technology transfer contract 'Text4Pose'.
@inproceedings{delmas2023posefix,
title={{PoseFix: Correcting 3D Human Poses with Natural Language}},
author={{Delmas, Ginger and Weinzaepfel, Philippe and Moreno-Noguer, Francesc and Rogez, Gr\'egory}},
booktitle={{ICCV}},
year={2023}
}