TL;DR
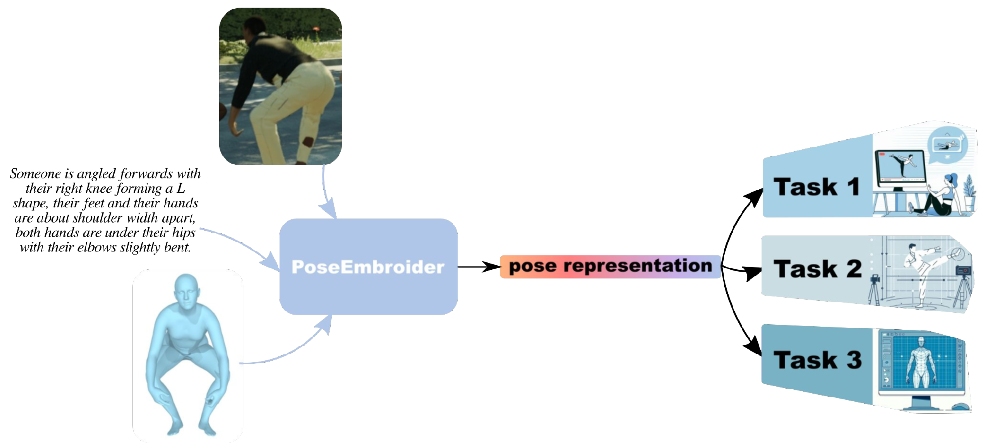
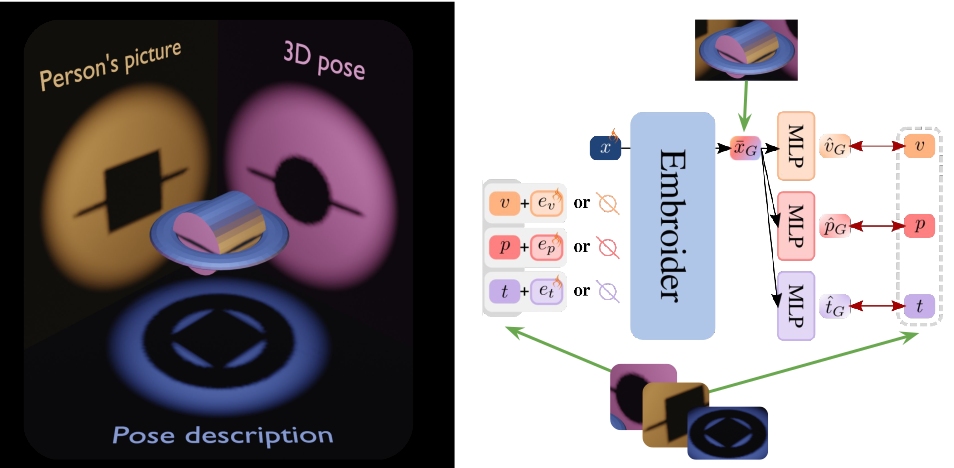
The PoseEmbroider builds on the idea that all modalities are only partial views of the same concept. Metaphorically, modalities are like 2D shadows of a 3D object. Each 2D shadow is informative in its own way, but is also only partial. Put together, they make it possible to reach a better understanding of the core concept. In this project, we train a model with all these three complementary, partial yet valuable, modalities so as to derive a generic 3D-, visual- and semantic- aware pose representation.
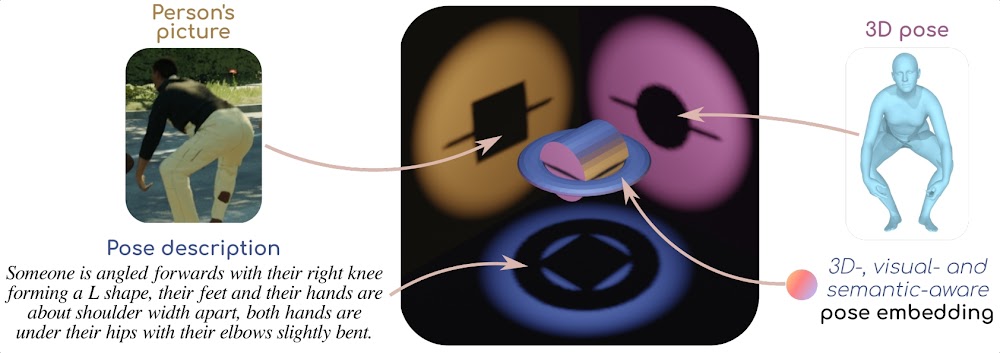
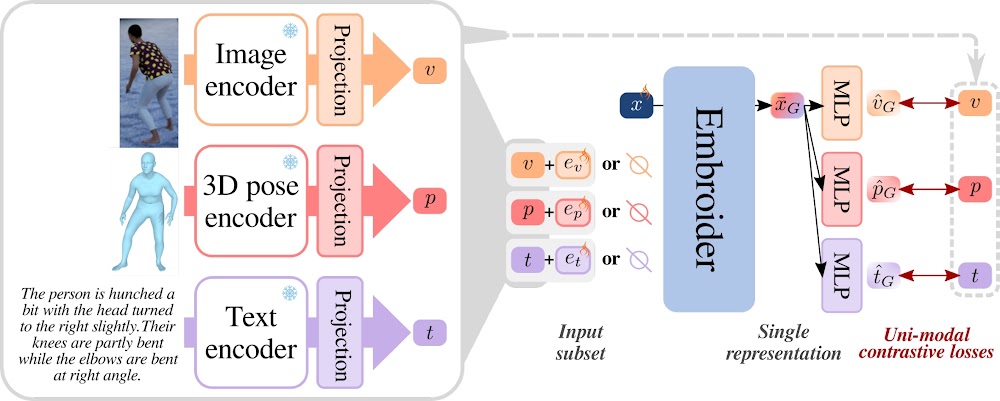
To do so, we use a subset of input modality embeddings obtained from pretrained, frozen modality-specific encoders. We feed these modality embeddings to a transformer, which outputs the generic pose representation through an added special token ("step 1"). This generic pose representation is then re-projected into uni-modal spaces, where it is compared to the original modality embeddings ("step 2"). Metaphorically, we try to approximate the 3D object in the picture from the available shadows (= step 1), then we assess the quality of the reconstruction by checking that the shadows are matching (= step 2).
We showcase the potential of our proposed representation on two downstream applications: human mesh recovery and the PoseFix corrective instruction task, where the goal is to generate a text explaining how to modify one pose into another.
Experiments on multi-modal retrieval also reveal that our proposed framework outperforms the classical "modality alignment" framework.