Human pose is key to multiple human-centric applications (art, sport, embodied AI...). Until recently, researchers had addressed underlying tasks where human pose is mostly studied in conjunction with images. The arrival of efficient language models fostered the incorporation of linguistic in vision frameworks, and thereby powered multi-modal applications. This thesis fits into this dynamic.
We aim to leverage Natural Language (NL) to bud human pose understanding in human-centric tasks. In contrast to prior endeavors, we juggle with static 3D human poses, images and detailed NL texts all together. We further explore novel multi-modal applications, requiring fine-grained understanding of the human pose.
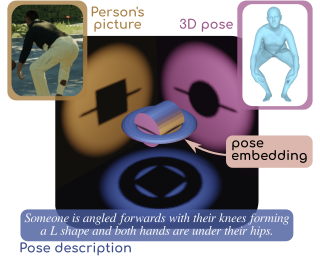
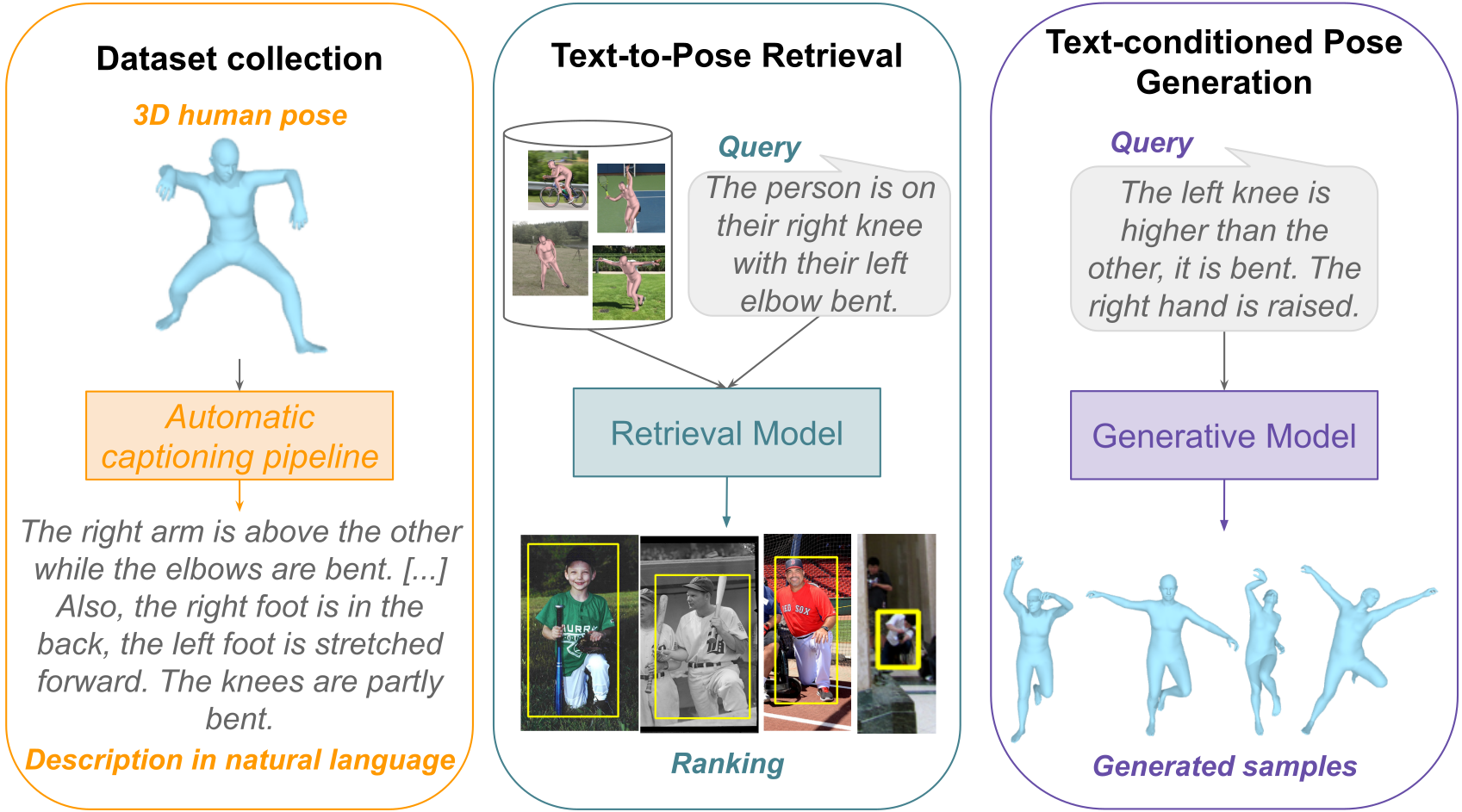
First, to alleviate the lack of data, we introduce new datasets linking 3D human poses with NL texts. We notably
investigate two settings. One where the text is a description of the target pose, and another where the text
provides modification instructions to reach the target pose from a source pose.
These datasets result both from (i) the collection of crowd-sourced annotations, and (ii) the automatic, rule-based generation of texts, which consists in the incorporation of classified pose measurements into templates sentences.
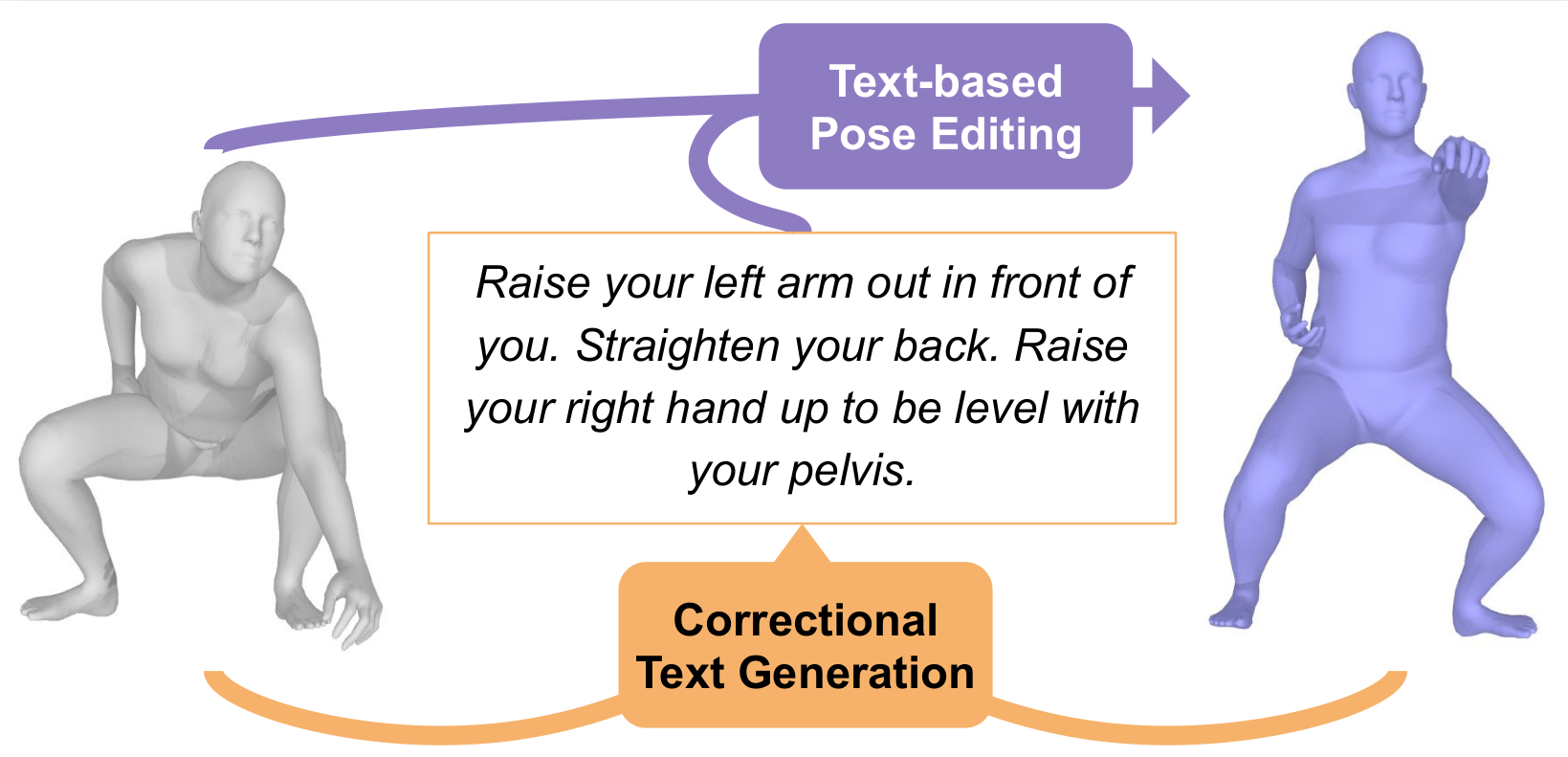
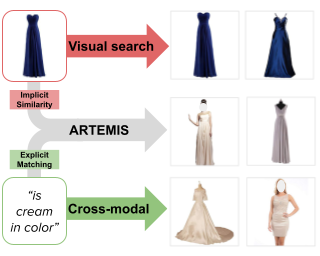
Next, we use these datasets to develop several cross-modal generation models like text-driven pose synthesis, pose captioning, text-guided pose editing and generation of textual posture feedback. Eventually, we connect 3D, text and images through a novel combinating framework, so as to derive a versatile, multi-modal pose representation, to be leveraged for downstream tasks akin to pose estimation or NL posture feedback from visual input.
In summary, we tackle multiple machine learning tasks entailing human pose understanding, thanks to the connection
of human pose and Natural Language.
@phdthesis{delmas2025linking,
title={Linking human poses with natural language},
author={Delmas, Ginger},
year={2025},
school={Universitat Polit{\`e}cnica de Catalunya}
}